


1. Introduction
Segmental duplications have received growing attention in the last few years and, indeed, they are enriched within the human and other mammalian genomes (e.g. Bailey et al., Reference Bailey, Gu, Clark, Reinert, Samonte, Schwartz, Adams, Myers, Li and Eichler2002, Reference Bailey, Church, Ventura, Rocchi and Eichler2004; Gu et al., Reference Gu, Wang and Gu2002; Samonte & Eichler, Reference Samonte and Eichler2002; She et al., Reference She, Jiang, Clark, Liu, Cheng, Tuzun, Church, Sutton, Halpern and Eichler2004; Cheng et al., Reference Cheng, Ventura, She, Khaitovich, Graves, Osoegawa, Church, DeJong, Wilson, Pääbo, Rocchi and Eichler2005). There is also emerging evidence that copy-number variation, generated by duplications and deletions of DNA segments that are 1 kb or larger in size, is abundant throughout human and Drosophila genomes (e.g. Iafrate et al., Reference Iafrate, Feuk, Rivera, Listewnik, Donahoe, Qi, Scherer and Lee2004; Li et al., Reference Li, Jiang, Mao, Balmain, Peterson, Harris, Rao, Havlak, Gibbs and Cai2004; Sebat et al., Reference Sebat, Lakshmi, Troge, Alexander, Young, Lundin, Månér, Massa, Walker, Chi, Navin, Lucito, Healy, Hicks, Ye, Reiner, Gilliam, Trask, Patterson, Zetterberg and Wigler2004; Perry et al., Reference Perry, Tchinda, McGrath, Zhang, Picker, Cáceres, Iafrate, Tyler-Smith, Scherer, Eichler, Stone and Lee2006; Dopman & Hartl, Reference Dopman and Hartl2007; Graubert et al., Reference Graubert, Cahan, Edwin, Selzer, Richmond, Eis, Shannon, Li, McLeod, Cheverud and Ley2007; Wong et al., Reference Wong, deLeeuw, Dosanjh, Kimm, Cheng, Horsman, MacAulay, Ng, Brown, Eichler and Lam2007; Emerson et al., Reference Emerson, Cardoso-Moreira, Borevitz and Long2008). A potential consequence of segmental duplications is gene duplication.
For a duplicate gene to be evolutionarily preserved, it must go through three steps. At the time of origination, a new duplicate gene is carried by a single individual in a population in heterozygous condition (origination step). The majority of new duplications would be lost soon after their appearance in the population, unless they are strongly advantageous (Kondrashov et al., Reference Kondrashov, Rogozin, Wolf and Koonin2002; Kondrashov & Koonin, Reference Kondrashov and Koonin2004). Only a small fraction increases its frequency and subsequently becomes fixed in the population. This fixation step has largely been neglected in the preceding literature. By focusing on duplicate genes created by whole genome duplication, previous work has mainly studied their evolutionary trajectories, starting from a population where the duplicate genes are already fixed (e.g. Haldane, Reference Haldane1933; Nei & Roychoudhury, Reference Nei and Roychoudhury1973; Bailey et al., Reference Bailey, Poulter and Stockwell1978; Kimura & King, Reference Kimura and King1979; Takahata & Maruyama, Reference Takahata and Maruyama1979; Li, Reference Li1980; Watterson, Reference Watterson1983; Force et al., Reference Force, Lynch, Pickett, Amores, Yan and Postlethwait1999; Walsh, Reference Walsh2003; Xue & Fu, Reference Xue and Fu2009). However, for duplicate genes created by segmental duplication, most of their fates are determined in this fixation step. Subsequently after this period, the fates of the fixed duplicate genes will finally be resolved (resolution step), through non-functionalization, neofunctionalization, subfunctionalization, or other selection processes. Non-functionalization refers to the process whereby one member of the duplicate pair is completely silenced by degenerative mutation(s). The population then returns to the original single-gene state. Alternatively, both genes may be indefinitely preserved by gaining a beneficial novel function (neofunctionalization; Ohno, Reference Ohno1970), by partitioning multiple functions of the ancestral gene via complementary loss-of-function mutations (subfunctionalization; Force et al., Reference Force, Lynch, Pickett, Amores, Yan and Postlethwait1999) or by positive selection for increased amount of gene product (Kondrashov et al., Reference Kondrashov, Rogozin, Wolf and Koonin2002). Because each of these processes may well proceed even in the pre-fixation period, the resolution step may sometimes be completed before the termination of the fixation step.
Here, we investigate another possibility, namely, enhanced preservation of the duplicate genes simply by the direct effect of gene duplication that masks deleterious loss-of-function mutations (Fisher, Reference Fisher1935). In two previous studies (Clark, Reference Clark1994; Lynch et al., Reference Lynch, O'Hely, Walsh and Force2001), this masking effect was only of minor importance in finite populations. Clark (Reference Clark1994) reported that the masking effect of gene duplication does not significantly affect the equilibrium frequency and that a duplicate gene actually behaves like a neutral mutation in his simulations. Lynch et al. (Reference Lynch, O'Hely, Walsh and Force2001) found only a two-fold increase in the fixation probability of a completely linked duplicate gene in large populations, although either one of the two duplicate genes is silenced in the early phase of evolution. However, there are several factors that were not fully explored yet, such as the dominance of deleterious mutations (haplo-insufficiency), the strength of mutation pressure and recombination between duplicate genes. Recently, it was found that, for genes with dominant lethal effect when their copy number is halved in diploid organisms (i.e. haplo-insufficient genes), the masking effect can retard the non-functionalization of a fixed duplication (Xue & Fu, Reference Xue and Fu2009; see also Takahata & Maruyama, Reference Takahata and Maruyama1979). This finding further raises a question of whether the masking effect also increases the fixation probability of a newly arisen duplicate gene.
Both Clark (Reference Clark1994) and Lynch et al. (Reference Lynch, O'Hely, Walsh and Force2001) used the double-null recessive model, whereby all two-locus genotypes have an equal fitness, except for double-null honozygotes that completely lack a gene function and therefore are lethal (haplo-sufficiency). Actually, in addition to a small number of haplo-insufficient genes, most, if not all, of loss-of-function mutations are slightly deleterious in heterozygous condition. The average degree of dominance of lethal mutations is indeed estimated to be about 0·02 in Drosophila melanogaster (Simmons & Crow, Reference Simmons and Crow1977).
In this paper, we explored whether such a small degree of dominance, together with high mutation pressure and recombination, is sufficient to become of evolutionary significance. It is demonstrated that the fixation of a newly arisen duplicate gene is substantially facilitated by loss-of-function mutations for a wide range of parameter values. The effect of masking deleterious mutations serves as an alternative mechanism to preserve both duplicate genes for long periods, which could increase the chance for neofunctionalization. To this end, we consider two models, single- and two-function models, with loss-of-function mutations.
2. Single-function model
Table 1 summarizes the abbreviations and parameters used to describe the fixation and resolution steps. Throughout we assume that right after the duplication event, both duplicate genes maintain the original function of the ancestral gene, with no intrinsic advantage or disadvantage to duplications.
Table 1. Parameters used for describing the fixation and resolution steps

Initially, we consider a single locus under mutation–selection–drift balance in a panmictic population of N diploids. A new duplicate gene is then created, with only a single chromosome carrying a duplicate gene (at an initial frequency of 1/(2N)). Unless otherwise stated, the gene is ‘essential’. Namely, the relative fitness (viability) of individuals harbouring no functional allele is 0 (i.e. selection coefficient s=1). Individuals carrying a single functional allele have a relative fitness of 1−h, and all other individuals carrying two or more functional alleles have a relative fitness of unity (Fig. 1a). We allowed three different degrees of dominance: h=0 (for double-null recessive genes), h=0·02 (for partially recessive genes) and h=1 (for haplo-insufficient genes). We also studied non-essential genes assuming s=0·1, with five different degrees of dominance (h=0, 0·002, 0·02, 0·2, or 1).

Fig. 1. Fitness scheme in (a) the single-function and (b) two-function models. A square and a triangle denote a protein coding region and a cis-regulatory region, respectively. Functionally intact regions are indicated in white, while degenerated regions with loss-of-function mutations are indicated in black.
Duplicate genes are either completely linked to each other (c=0, where c denotes recombination rate per generation between the two loci) or freely recombining (c=0·5). We also consider another case of c=10−4, which represents the average recombination rate between adjacent genes of D. melanogaster (Lindsley & Zimm, Reference Lindsley and Zimm1992).
In the single-function model, loss-of-function mutations that completely disrupt the function occur at a rate of u c=10−3 per locus per generation. It is assumed that the mutations are unidirectional and that backward mutations do not occur. We further ignore advantageous mutations that lead to neofunctionalization.
To study the evolutionary fates after gene duplication (fixation and resolution steps), we performed stochastic simulations based on a gamete-based model (Lynch & Force, Reference Lynch and Force2000) over a range of population size (N=50–105). Given the frequencies of gametes in the previous generation, we first calculated the expected frequencies of zygotes after mutations, random mating and viability selection. Based on these expectations, the actual zygote frequencies are obtained by sampling N individuals using the improved pseudo-sampling method (Kimura & Takahata, Reference Kimura and Takahata1983). Finally, the expected frequencies of gametes after recombination are determined for the next generation. In this gamete-based model, mutation, selection and recombination are all treated as deterministic processes (Lynch & Force, Reference Lynch and Force2000).
To investigate the fixation probability and fixation time of a newly arisen duplicate gene in the fixation step, the above cycle is repeated until the duplicate gene reaches fixation or is lost from the population, irrespective of the functional state of the duplicate gene. At least 100 fixation events were simulated for each set of parameter values. To investigate the evolutionary fates in the resolution step, the simulation cycle is further continued until one member of a duplicate pair becomes silenced (non-functionalization). If functional alleles are preserved for 100N generations at both loci, the simulation run is halted and the next run is initiated.
(i) Fixation step in the single-function model
For a newly arisen duplicate of an essential gene (with s=1), the fixation probability is given in Table 2, together with the mean time to fixation. In the table, the results are scaled in units of neutral expectations (1/(2N) for the fixation probability, or 4N generations for the fixation time). When Nu c⩽0·1, both fixation probability and time are not much different from their neutral expectations, irrespective of s, h and c values. However, when Nu c⩾0·5, the fixation probability is substantially increased and, concomitantly, the fixation time is decreased. This result implies that under sufficiently high mutation pressure, a duplicate gene becomes selectively advantageous by masking the deleterious effect of recurrent loss-of-function mutations. While this masking effect was more evident with larger h values, even an h value as small as 0·02 had a significant impact. Recombination also has an important effect on the evolution of duplicate genes. When the new duplicate gene is completely linked to the original gene (c=0), its advantage was not particularly noticeable, except for haplo-insufficient genes (h=1) under high mutation pressure (Nu c>1). By contrast, for an unlinked copy (c=0·5), substantial increase in the fixation probability and decrease in fixation time were observed when Nu c⩾0·5, irrespective of the degree of dominance. Although less intense in its magnitude, the same tendency was detected even for the recombination rate as small as c=10−4.
Table 2. Scaled probability and time of fixation of a newly arisen duplicate gene in the single-function model with uc=10 −3 and s=1

90% interval of fixation time is represented in the parentheses.
We analysed the joint effects of h and s more in depth under c=0·5, and obtained the following two findings as summarized in Table 3. First, the fixation probability and time did not much differ between s=1 and 0·1 except for the case of h=0·02; by contrast, the degree of dominance (h) of mutations had stronger effects. Second, when hs was kept constant, the selective advantage of a duplicate gene was more evident for larger h (and smaller s); for instance, for hs=0·02, the deviation from neutrality was more substantial when (h, s)=(0·2, 0·1) than when (h, s)=(0·02, 1). Likewise, for hs=0·002, the effect of selection was more obvious when (h, s)=(0·02, 0·1) than when (h, s)=(0·002, 1).
Table 3. Scaled probability and time of fixation of a newly arisen duplicate gene in the single-function model when N=50 000, uc=10 −3 and c=0·5

90% interval of fixation time is represented in the parentheses.
(ii) Resolution step in the single-function model
For the resolution step, we focus on essential genes with s=1. In the single-function model, non-functionalization is usually inevitable and one of the duplicate genes will be silenced sooner or later. Indeed, our simulations demonstrated that either when h=0 or c=0, non-functionalization was always completed within 100N generations unless Nu c=0·05 (Figs 2a–d, g and 3 a). Non-functionalization occurred with an approximately equal frequency at either of the two loci when c=0 (Fig. 2a–c), while it happened mostly at the new locus when h=0 and c=10−4 or 0·5 (Fig. 2d and g). By contrast, when h>0 and c=0·5, functional alleles were largely preserved at both loci even after 100N generations if the mutation pressure is sufficiently high (Fig. 2h and i). Although larger Nu c values are required, the same tendency was seen with c=10−4 (Fig. 2e and f).

Fig. 2. Evolutionary fates of duplicate genes after 100N generations in the single-function model. Results for three different recombination rates (c=0, 10−4, or 0·5) and three different degrees of dominance (h=0, 0·02, or 1) are illustrated; u c=10−3 and s=1 are assumed throughout. For each combination of parameter values, simulations were performed with nine different population sizes (N=50–105). The figure shows the relative frequencies of three possible outcomes: non-functionalization at the new locus (grey), non-functionalization at the original locus (white) and preservation of both loci (black).
Time course of non-functionalization is illustrated in Fig. 3 for the case of c=0·5 and Nu c=5. When h=0, most non-functionalization events occurred within 10N generations, particularly at the new locus (Fig. 3a). When h=0·02, non-funcitonalization occurred gradually after 10N generations, but both genes were still functional in more than 60% of simulation runs even when 100N generations have elapsed since the appearance of a new duplicate gene (Fig. 3b). When h=1, non-functionalization is almost completely prevented from occurring (Fig. 3c). Indeed, the frequencies of functional alleles after 100N generations were kept higher than 0·8 at both loci when h=1 (Fig. 4b), while asymmetry in allele frequency between the two loci was stronger for h=0·02 (Fig. 4a).

Fig. 3. Temporal increase in non-functionalization in the single-function model. Parameter values are N=5000, u c=10−3, c=0·5 and s=1, with (a) h=0, (b) h=0·02, or (c) h=1. The figure shows the cumulative frequencies of three possible outcomes (conditional on the ultimate fixation of the new duplicate gene): non-functionalization at the new locus (grey), non-functionalization at the original locus (white) and preservation of both loci (black).

Fig. 4. Frequencies of functionally intact alleles at the two loci after 100N generations in the single-function model. Parameter values are N=5000, u c=10−3, c=0·5 and s=1, with (a) h=0·02 or (b) h=1. The value of n in the parenthesis indicates the observed number of simulation runs in which both loci remained polymorphic for 100N generations.
So far, we have analysed the fixation and resolution steps separately. To contrast the present observations with the results of Lynch et al. (Reference Lynch, O'Hely, Walsh and Force2001), we here consider the probability of preservation of a newly arisen duplicate gene after 100N generations. There are two possibilities: non-functionalization of the original gene (and therefore permanent preservation of the newly arisen duplicate gene) and preservation of both original and new duplicate genes. Table 4 gives the combined probability scaled in units of the neutral expectation (=1/(2N)). Lynch et al. (Reference Lynch, O'Hely, Walsh and Force2001) found that irrespective of the recombination rate (c=0 or 0·5), the scaled combined probability was ~0·5 in small populations (Nu c<0·1), assuming haplo-sufficient essential genes (h=0 and s=1). In large populations, while the scaled probability was kept almost constant (~0·5) for freely recombining loci, it increased up to unity under complete linkage (see Fig. 3 in Lynch et al., Reference Lynch, O'Hely, Walsh and Force2001). In the present analysis, we found much higher increase in the combined probability for h>0, especially when there was a nonzero opportunity of recombination between the two loci (Table 4). Importantly, this increase is largely contributed by long preservation of both duplicate genes, which cannot be seen under conditions studied in Lynch et al. (Reference Lynch, O'Hely, Walsh and Force2001). These results also highlight the importance of the degree of dominance in promoting the preservation of a new duplicate gene under high mutation pressure.
Table 4. Scaled probability of preservation of a new duplicate gene under uc=10 −3 and s=1

95% confidence limit of the probability based on Poisson statistics (Gehrels, Reference Gehrels1986) is represented in the parentheses.
3. Two-function model
We here extend the single-function model developed in the preceding section and consider an ancestral gene that has two independently mutable subfunctions. In this two-function model, each of the two duplicate genes is subject to two distinct classes of degenerative mutations: regulatory mutations that eliminate only one of the two subfunctions and coding mutations that disrupt the entire gene functions simultaneously. The former class occurs at a rate u r=10−3 per locus per generation for each subfunction, and the latter also occurs at a rate u c=10−3. We here focus on essential genes; the relative fitness values are set to be 0 for individuals carrying no functional allele for either subfunctions, (1−h)2 for those carrying only a single functional allele for each subfunction, 1−h for those carrying one functional allele for one of the subfunctions together with two or more functional alleles for the other subfunction, and 1 for those carrying two or more functional alleles for both subfunctions (multiplicative fitness model, Fig. 1b).
As in the single-function model, an initial population was assumed to be in mutation–selection–drift equilibrium. Each run of simulations was started by introducing a single copy of haplotype with two fully functional alleles at both loci.
Because subfunctionalization may occur in the two-function model (Force et al., Reference Force, Lynch, Pickett, Amores, Yan and Postlethwait1999), we repeated at lease 100 simulation runs, each leading to either non-functionalization, subfunctionalization, or preservation of functional alleles at both loci (after 100N generations).
(i) Fixation step in the two-function model
Because u c and u r are all set to be 10−3, the total mutation rate is three times as large as in the single-function model. This entails even higher pressure for degenerative mutations, further leading to greater probabilities for the fixation of a new duplicate gene (Table 5). Otherwise, the results were essentially the same as in the single-function model.
Table 5. Scaled probability and time of fixation of a newly arisen duplicate gene in the two-function model with uc=ur=10 −3 and s=1

90% interval of fixation time is represented in the parentheses.
(ii) Resolution step in the two-function model
As in the previous study (Lynch & Force, Reference Lynch and Force2000; Lynch et al., Reference Lynch, O'Hely, Walsh and Force2001), subfunctionalization was observed only for small Nu c values, say Nu c⩽0·5, irrespective of h values (Fig. 5). The probability of subfunctionalization was not much affected by recombination rate. As in the single-function model, joint preservation of fully functional alleles at both loci was facilitated under high mutation pressure so long as h⩾0·02 and c⩾10−4. The transition from non-functionalization to preservation occurred in a narrow range of Nu c values.

Fig. 5. Evolutionary fates of duplicate genes after 100N generation in the two-function model. Results for three different recombination rates (c=0, 10−4, or 0·5) and three different degrees of dominance (h=0, 0·02, or 1) are illustrated; u c=u r=10−3 and s=1 are assumed throughout. For each combination of parameter values, simulations were performed with nine different population sizes (N=50–105). The figure shows the relative frequencies of four possible outcomes: subfunctionalization (cross-hatched), non-functionalization at the new locus (grey), non-functionalization at the original locus (white) and preservation of both loci (black).
4. Probability of fixation of functional duplications
As shown above, when c=0·5, h>0 and Nu c>1, both members of a duplicate pair can functionally be preserved during and after the fixation of the newly arisen duplicate gene (Fig. 2h and i). Here, we refer to the probability that a new duplicate gene is fixed while keeping both genes functional as the ‘functional fixation’ probability. To obtain the probability of functional fixation for arbitrary s and h values, consider selection acting on a rare duplication in the single-function model. Assume that a duplication occurs in a sufficiently large population at mutation–selection equilibrium. Let q e denote the equilibrium frequency of the non-functional allele at the original locus. For large populations (Nu c>1), q e is given by

(Crow & Kimura, Reference Crow and Kimura1970).
The expected change in the frequency (x) of a rare, unlinked duplicate gene per generation is given by
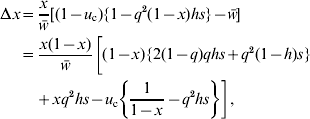
where ![]() is the mean fitness of the population and q is the frequency of the non-functional allele at the original locus. Unlike in the standard derivation, the effect of recurrent mutation cannot be neglected here, because the selective advantage of the new duplicate gene is of the same order of magnitude as the mutation rate. When x is small, we may replace q by q e. Then, we see an increase of x (Δx>0) when 0<h⩽1, implying the selective advantage of the new duplicate gene at low frequencies. This advantage in large populations can account for the enhanced fixation and preservation of duplicate genes under large Nu c and c=0·5 (Table 2, Fig. 2h and i).
is the mean fitness of the population and q is the frequency of the non-functional allele at the original locus. Unlike in the standard derivation, the effect of recurrent mutation cannot be neglected here, because the selective advantage of the new duplicate gene is of the same order of magnitude as the mutation rate. When x is small, we may replace q by q e. Then, we see an increase of x (Δx>0) when 0<h⩽1, implying the selective advantage of the new duplicate gene at low frequencies. This advantage in large populations can account for the enhanced fixation and preservation of duplicate genes under large Nu c and c=0·5 (Table 2, Fig. 2h and i).
The fixation probability of a mutation can be approximated by twice the selective advantage of the heterozygote (Kimura, Reference Kimura1957; Gale, Reference Gale1990). This may hold true for a duplicate gene. In the present case, this selective advantage may be obtained by taking the limit x→0 in the right-hand side of eqn (2) and then replacing q by q e. This yields approximately the functional fixation probability (P ff) as
As shown graphically in Fig. 6, the predicted probability (3) increases from 0 to 2u c rapidly as h increases. The prediction is in close agreement with the simulated probabilities of functional fixation (Table 6). When h=0, the selective advantage of a new duplicate gene becomes ~0. Therefore, loss-of-function mutations accumulate on neutral duplicate genes immediately after the origination, leading to non-functionalization predominantly at the new locus.

Fig. 6. The predicted probability of functional fixation as a function of h. (a) u c=10−3 and (b) u c=10−5, with s=1 (solid line) or s=0·1 (dotted line).
Table 6. Probability of functional fixation and its theoretical prediction (Pff) in the single-function model with uc=10 −3

For small populations, q e becomes smaller than the equilibrium frequency given by the formulae (1) due to the purging effect (Kirkpatrick & Jarne, Reference Kirkpatrick and Jarne2000; Glémin, Reference Glémin2003). This reduction in the frequency of non-functional alleles decreases the selective advantage of a new duplicate gene, which, in turn, reduces the probability of functional fixation.
When the two loci are completely linked (c=0), functional fixation as defined above may be considered as fixation of the functional two-copy allele (designated ff, where f refers to a functional allele at a single locus). The expected change per generation in the frequency (y) of the ff allele is given by
This equation has been obtained by Lynch et al. (Reference Lynch, O'Hely, Walsh and Force2001) for the double-null recessive model (h=0). In eqn (4), the mutation rate u c is multiplied by two because mutation at either of the two loci destroys an ff allele. Therefore, the effect of mutation that hinders functional fixation is twice as strong as in the free recombination case (c=0·5; see eqn 2). Consequently, in the absence of recombination, the selective advantage of a duplication cannot be significant enough to overcome the counteracting effect of loss-of-function mutation. Indeed, our simulations have found a complete lack of functional preservation of both loci when c=0 (Fig. 2a–c). Because an ff allele is converted to f0 or 0f allele (0 refers to a non-functional allele) with equal probability, non-functionalization occurs equally at the original and new loci for fixed duplications.
We have also seen in the above simulations that reduced recombination decreases the selective advantage of a new duplicate gene (compare Fig. 2e and f with h and i, respectively). Roughly speaking, recombination greater than the mutation rate (c>u c) is needed for ample opportunities of functional fixation (Table 6).
In conclusion, with a sufficient amount of recombination (c>u c), the probability of functional fixation approaches 2u c in large populations (Nu c>1) as h increases, and the transition of the probability from 0 to 2u c occurs in a narrow range of h, especially when u c is small.
5. Discussion
Most theoretical studies of gene duplication have been concerned with the evolutionary consequences of ancient whole-genome duplications, focusing mainly on the resolution process leading to non-functionalization, starting from a population where the duplicate genes are already fixed (e.g. Haldane, Reference Haldane1933; Nei & Roychoudhury, Reference Nei and Roychoudhury1973; Bailey et al., Reference Bailey, Poulter and Stockwell1978; Kimura & King, Reference Kimura and King1979; Takahata & Maruyama, Reference Takahata and Maruyama1979; Li, Reference Li1980; Watterson, Reference Watterson1983; Force et al., Reference Force, Lynch, Pickett, Amores, Yan and Postlethwait1999; Walsh, Reference Walsh2003; Xue & Fu, Reference Xue and Fu2009). On the other hand, for duplicate genes created by segmental duplication, the fixation process is more important because the majority of duplications would be lost or silenced before reaching a significant frequency in a population (Kondrashov et al., Reference Kondrashov, Rogozin, Wolf and Koonin2002).
Here, we showed that purifying selection against loss-of-function mutations increases the fixation probability of a new duplicate gene (Tables 2, 3 and 5) and enhances the preservation of functional alleles at both duplicate loci (Figs 2, 3 and 5, Table 6). In large populations (Nu c>1), the probability that a new duplicate gene is fixed while preserving both genes functional increases from 0 to 2u c rapidly as h increases from 0 to 1. Indeed, the transition from 0 to 2u c occurs in a narrow range of h: for example, when u c=10−5, it occurs in the range 0–0·02 (Fig. 6). Although recombination is also important for a new duplicate gene to be selectively advantageous, the required amount of recombination is small (of the same order of magnitude as the mutation rate, >u c). In sum, the fixation of a newly arisen duplicate gene can be enhanced under a wide range of reasonable conditions.
A duplicate gene is equivalent to a modifier that reduces the level of dominance of mutations (Fisher, Reference Fisher1928; Wright, Reference Wright1929), in the sense that both restore the fitness of mutant heterozygotes to the same optimum of the wild-type. Indeed, the selective advantage of u c can be applied to a dominance modifier that gives complete dominance to the wild-type allele (the maximum case, Fisher, Reference Fisher1929; Haldane, Reference Haldane1930; Wright, Reference Wright1934; the selective advantage becomes 2u c in these papers, ignoring mutations at the modifier locus). While these authors focused on the rate of frequency change of the modifier, we showed here that the probability of functional fixation becomes 2u c.
Our findings account for the much less enhancement of the fixation of a new duplication in Clark (Reference Clark1994) and Lynch et al. (Reference Lynch, O'Hely, Walsh and Force2001). Both Clark (Reference Clark1994) and Lynch et al. (Reference Lynch, O'Hely, Walsh and Force2001) are based on the double-null recessive model (h=0). In addition, Clark (Reference Clark1994) assumed no recombination between the duplicate genes (c=0) as well as low mutation pressure (Nu c⩽0·1). Especially under the condition of Clark (Reference Clark1994), we found almost no increase in the fixation probability (Table 2), which is consistent with his result. In any case, when h=0, recurrent deleterious mutations do not enhance the preservation of functional copies (Table 6; Fig. 6).
Recent sequencing of mutation accumulation lines in several model organisms has provided estimates of mutation rate per site per generation of 0·3–21×10−9 (Denver et al., Reference Denver, Morris, Lynch and Thomas2004; Haag-Liautard et al., Reference Haag-Liautard, Dorris, Maside, Macaskill, Halligan, Charlesworth and Keightley2007; Lynch et al., Reference Lynch, Sung, Morris, Coffey, Landry, Dopman, Dickinson, Okamoto, Kulkarni, Hartl and Thomas2008). Assuming a mutational target size of ~1 kb, the mutation rate per locus would then be approximately 10−5–10−6. These figures appear compatible with previous estimates from specific locus tests (10−4–10−6; see for review, Woodruff et al., Reference Woodruff, Slatko and Thompson1983; Drake et al., Reference Drake, Charlesworth, Charlesworth and Crow1998). Given these mutation rates, it is not unexpected to see the Nu c values as high as 10 in certain species. As we have seen above, the masking effect of duplication could have important consequences for genome evolution in these species. When u c=10−5, the average degree of dominance of mutations (h~0·02) estimated in Drosophila (Simmons & Crow, Reference Simmons and Crow1977) is just enough to reach the maximum level of the functional fixation probability (~2u c; see Fig. 6b).
In this study, we did not consider potential disadvantage of gene duplication caused by imbalanced gene dosage. Indeed, segmental duplications in the human genome are often associated with diseases, which, together with other structural changes, are called genomic disorders (Stankiewicz & Lupski, Reference Stankiewicz and Lupski2002). There is further evidence for deleterious effects associated with segmental duplications. Segmental duplications are created by non-allelic homologous recombination (NAHR; ectopic recombination) between repeated sequences (e.g. Goldberg et al., Reference Goldberg, Sheen, Gehring and Green1983; Roeder, Reference Roeder1983; Chance et al., Reference Chance, Abbas, Lensch, Pentao, Roa, Patel and Lupski1994). The occurrence rate of NAHR was estimated to be 0·4–170×10−6 per gene per generation in Drosophila (Gelbart & Chovnick, Reference Gelbart and Chovnick1979; Shapira & Finnerty, Reference Shapira and Finnerty1986; Watanabe et al., Reference Watanabe, Takahashi, Itoh and Takano-Shimizu2009). This rate is more than 400 times larger than the origination rate of gene duplication estimated from the genome sequence analysis (0·001×10−6; Lynch, Reference Lynch2007), implying that the majority of duplications are deleterious and rapidly eliminated by purifying selection before reaching fixation.
While neofunctionalization and subfunctionalization have possibly been involved in the retention of duplicate genes in the later stages of evolution, the selective advantage of gene duplication via its masking effect must have played a more important role, together with its direct disadvantage, in the early stage before fixation. If different classes of genes are characterized by distinct levels of heterozygous fitness effects (hs), then this could be the primary reason for the non-random distribution of duplicate genes, where certain types of genes, namely those associated with immunity and defense, membrane surface interactions, drug detoxification and growth/development, are overrepresented (Bailey et al., Reference Bailey, Gu, Clark, Reinert, Samonte, Schwartz, Adams, Myers, Li and Eichler2002; Nguyen et al., Reference Nguyen, Webber and Ponting2006; Perry et al., Reference Perry, Tchinda, McGrath, Zhang, Picker, Cáceres, Iafrate, Tyler-Smith, Scherer, Eichler, Stone and Lee2006; Dopman & Hartl, Reference Dopman and Hartl2007; Graubert et al., Reference Graubert, Cahan, Edwin, Selzer, Richmond, Eis, Shannon, Li, McLeod, Cheverud and Ley2007). However, the distribution of fitness effects of loss-of-function mutations and spontaneous duplications remains largely undetermined.
There is evidence that duplicate genes are more enriched for haplo-insufficient than haplo-sufficient genes (Kondrashov & Koonin, Reference Kondrashov and Koonin2004; see Qian & Zhang, Reference Qian and Zhang2008, for a contrasting view). While Kondrashov et al. (Reference Kondrashov, Rogozin, Wolf and Koonin2002) proposed an increased protein dosage as the primary factor promoting the persistence of duplicate genes (see also Kondrashov & Koonin, Reference Kondrashov and Koonin2004), the masking effect of gene duplication is an alternative explanation for the differential preservation of duplicate genes between the two classes of genes with distinct heterozygous fitness effects (hs). A long-term persistence of duplicate genes due to the masking effect may increase the chance for neofunctionalization to occur in the future generations.
We thank Hideki Innan for help with simulation procedures and Fyodor Kondrashov for suggestions. This work was supported by a Grant-in-Aid for Scientific Research (C) from the Ministry of Education, Culture, Sports, Science and Technology of Japan (TT-S).












